cacheCopy is a smart little tool that will select and save for you all those JPG images that your browser throws into the cache folders every time it opens a new Web page. The whole process is fully automated, as cacheCopy will find the corresponding cache folders by itself and will obediently put all the images found in a folder of your choice.
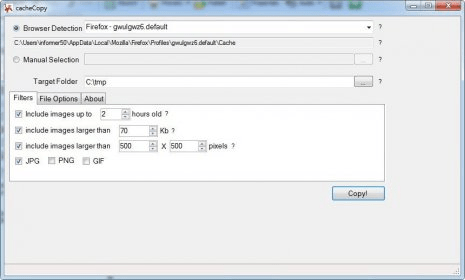
This open-source project comes with a simple interface that requires little or no work on your side. cacheCopy is designed to work with both Internet Explorer and Mozilla Firefox, though it shows evident problems detecting the latter. Once he detects the browsers installed in your system, it will provide you with the tentative cache folder that it will scan looking for JPG files. However, you are also given the choice of selecting the path for your browser’s cache folder manually.
When it comes to the image files themselves, you can set the program to store only those that fulfill certain requirements. Thus, you can set the maximum time (in hours) during which the images to be selected have been stored in your computer. Besides, you can also discriminate the files to recover by their size and/or their weight. According to this, you can tell the program to select (or ignore) those images larger than a specific amount of Kb, and those larger than X number of pixels. In order to make your selection more precise, you can tick each of these parameters on or off, and combine them in whichever way it best fits your needs.

With Free Cache View you can view and extract any video clips from web browsers.








Comments